Man, these past couple of days have sucked.
Before you read this, if you're running BloatFE or 8bloat and aren't on single instance mode with a trusted instance, please update your software. Upstream Bloat has pushed changes. Frankly I don't feel like auditing more code after this whole experience. If you apply my patch, you're safe. I did make a rudimentary patch that fixes the issue here. For users of 8bloat, you don't need to apply a patch, just upgrade to the pseudoversion v0.0.1. There's also a link to a patch of the commit on Sourcehut here.
Alternatively, set single_instance to use a trusted server. An actually trusted one, the upstream server is able to exhaust the system memory, and in some niche situations create unexpected resource utilisation. For the prior, this could lead to other services being ungracefully killed. This could lead to data loss, and other nasty issues outside of denial-of-service.
Terminology
@r is short for @r@freesoftwareextremist.com, the author of BloatFE.
BloatFE refers to the Bloat client by @r.
8bloat is my fork of BloatFE.
Bloat (without the FE) refers collectively to 8bloat and BloatFE.
Upstream server refers to the server running the Mastodon API being used by Bloat.
Bloat instance refers to the running version of Bloat on a server.
but first, background
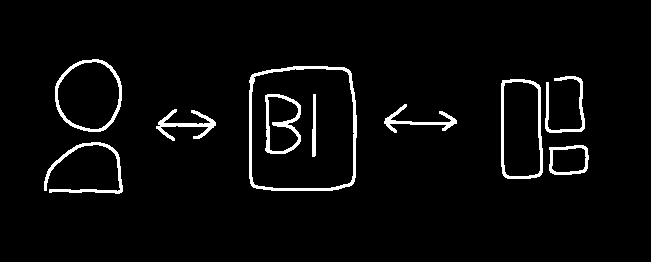
BloatFE is a Pleroma client created by @r@freespeechextremist.com. It acts as a proxy of sorts that sits between a user and an instance. The user authorises the Bloat instance to make requests on its behalf. Bloat then adapts the Mastodon API to basic HTML and sends it to the client. It also adapts POST forms to work with the API and UI. Users can run the client locally and connect to it with their web browser, but most people use instances that are accessible over the internet.
8bloat is a hard, independent fork of BloatFE that also supports Mastodon. You can sort of think of its relationship to BloatFE like the relationship between Akkoma and Pleroma. It's a fast-paced, quickly moving fork that operates on its own and adds many features/fixes/improvements while generally trying to not stray from the design language and unique properties of BloatFE that make it special. The codebase at this point is mostly unrecognisable, except for the UI. It is a spider den project, authored by yours truly.
This security vulnerability was discovered while I was doing an audit of 8bloat's code and hardening parts of the codebase.
the (full) issue
Bloat uses Go's default http.Client which is located at http.DefaultClient. This client is not configured to be secure by default, and unfortunately Bloat uses it. This causes two issues.
One, is that there is no timeout. When Bloat makes an HTTP request to a remote server the server can cause the client to hang if there is no timeout configured by the reverse proxy. This is low severity because all you can really do is cause minimal resource utilisation, and cause file descriptor exhuastion which only really affects Bloat in applicable cases. Because the request gets cancelled if the client cancels, this means it can be effectively dealt with with the reverse proxy. Generally speaking, issues that stem from size/time issues between the client and Bloat aren't defacto considered to be security issues. You should use a reverse proxy and configure it to your needs. However, if you /do/ trust the clients, this can lead to unexpected resource utilisation. This can cause issues, but it isn't disasterous, and is niche. It also doesn't require a patch, but the patch does include a request timeout for safety purposes. This is moreso a failure of the security model so to speak that might give an admin a couple of hours of a headache before filing a bug report.
The second one is that the HTTP client places no bounds on the size of the body returned from the server. This is where the big issues start.
When Bloat is communicating with an upstream server, it does so using HTTP requests. Oversimplfiying a bit, these requests have a set of headers (a basic key/value pair basically) and a body. The body contains the actual content of the page. In the case of the Mastodon API, it returns objects in the form of JSON. In Go, the standard library has a library just for parsing that data, which is used in Bloat.
However, at no point in the process of reading the body does it place limits on the size of the data. An attacker could just return a really large JSON file and fill up the memory of the machine running Bloat. This is trivial to do, I managed to make a small twenty line server that did just this in like two minutes. All an attacker would need to do is make Bloat call its evil API once and have their garbage data loaded into memory.
mothbro: Okay, so a really big file? If I have a lot of spare RAM (say ten gigabytes) and a slow connection or short request timeout, how could this be filled?
Good question! Go's HTTP client by default also decompresses GZIPed responses. This makes the attack even more practical by not requiring much bandwidth for the evil API. I created an eleven megabyte file that would fill those ten gigabytes in seconds. This can be done because the data that gets returned can be garbage; easily compressibe garbage that's repetitive. A file that's pretty much all the number zero is so easy to compress that you can get insane ratios like those.
mothbro: Hmm. So, alright, we can fill up the memory. This seems like a small issue. Why is this classified as severe by you? Just seems like a basic denial-of-service.
Yes, Bloat is probably going to be killed. But the devil is in the details, and if you aren't super familiar with server administration or Linux then you might gloss over them. Notice how the issue here is memory exhaustion, because it leads to more issues than just a denial of service.

On Unixy systems such as Linux there's a little devil called the "OOM killer" (or here I'll call him Oomy because that sounds cute.) Oomy gets called in when the system is about to run out of memory. He's tasked to look at the processes on a machine and determine what needs to be killed. Oomy, looking at the memory, will generally just kill the process using the most memory. This works most of the time, but in many situations -- ones that people will likely be in considering the userbase -- this can cause issues.
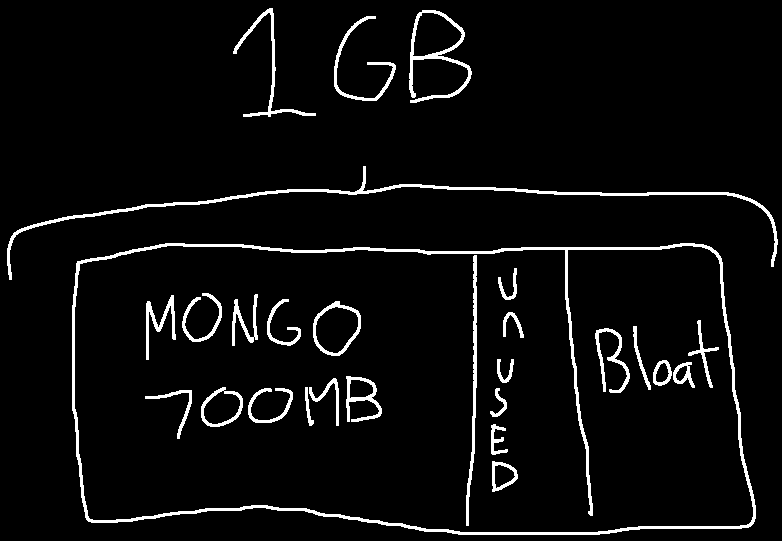
Imagine the following situation. You have a 1GB VPS from Hetznode that you run MongoDB on. MongoDB is taking up 700MB of memory. It must be gracefully terminated to prevent data loss.
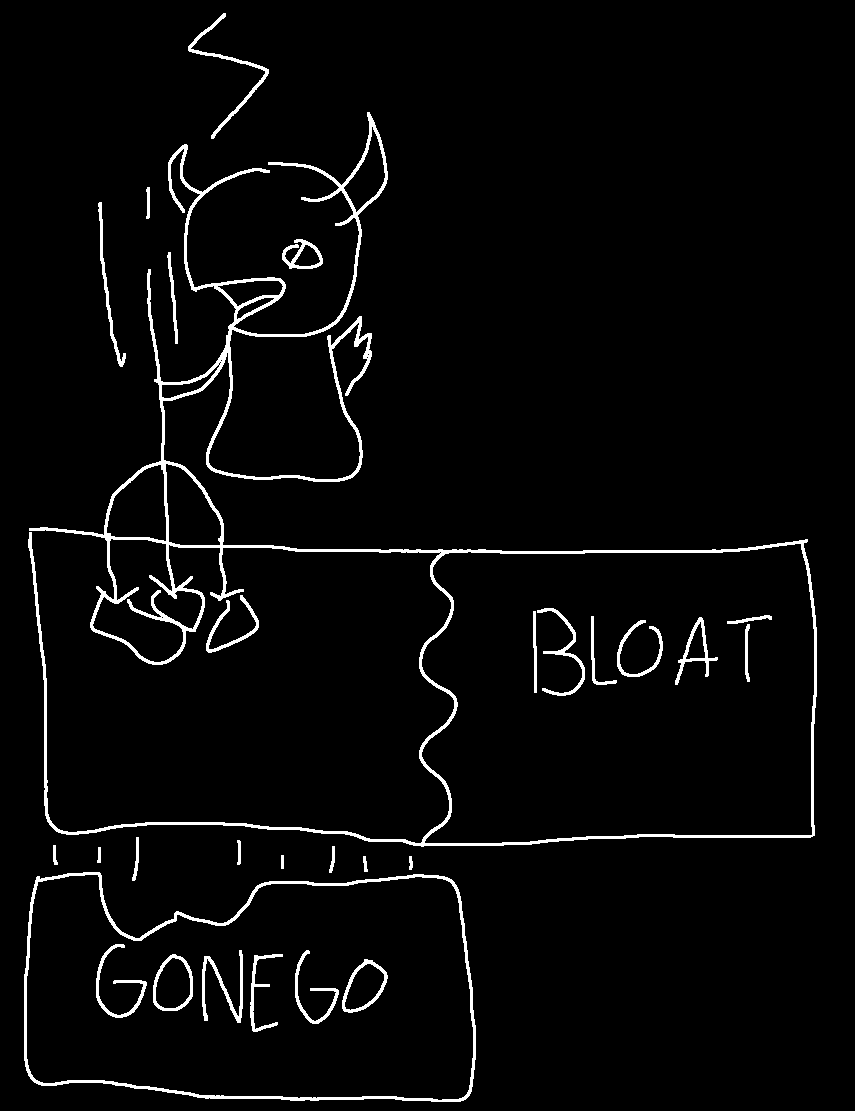
Then, you have Bloat being exploited and filling up the rest of the memory. Because Oomy sees that MongoDB is taking up the most memory, it kills it, causing corruption/data loss. Now all the services that depend on it get shut down, and you just lost your webscale database of anime girls. Hopefully now it's clear why a memory exhaustion issue is so severe. Can this be configured? Yes. But not a lot of people -- especially the users of Bloat who are hobbyists -- are going to configure such a low-level detail. They'll probably configure rate limits, but this issue can be exploited in just one request.
Generally, security issues that affect other services are considered far more severe because you cannot predict what will be affected. It could be a Pleroma instance using that memory, or a hospital's patient intake services. When Oomy kills services, it kill -9s, no more CPU time, and doesn't let the process gracefully stop itself.
There is also other concerns, like the fact doing this prevents the system from using unused memory to cache the disk, which increases load on the disk and slows the system down. There's farther reaching implications than just "denial-of-service", that's just one symptom of memory exhaustion this way. If you run a service, chances are it'll automatically restart. This can make this issue a loop and exist long-term if not checked.
mothbro: Okay, but can't this be mitigated? Can't you configure the system to prevent this?
Yes, but a paranoid configuration is not always a practical one, and is a low-level detail for both the userbase and even for most people. Most systems require flexibility in memory utilisation, where at some points one process uses more memory, and at another a second process comes in and uses more.
It's difficult to set a realistic expectation of memory consumption when you don't even know what that memory consumption could be, because it's literally infinite.
I think it's a safe assumption to say that enough people using this software don't have this configured and are at risk.
This issue doesn't stop being an issue with Bloat because the operating system has its own means of dealing with it. Yes, you can harden your system, but it's easier to apply a patch that gives predictable results in the first place and fixes the fundemental issue. The advisory would've been the same, just with a worse end-result. There would be twelve different instructions for systems to mitigate the issue which would be confusing.
A self-hoster running this on a VPS using the software would probably be unaware that this option even exists. We don't have data, so we should err on the side of caution, considering the potential consequences of this.
Enough people are assumed to be at risk. An important thing to consider in issues like this is /who's actually affected/.
the fix
Basically, the patch for BloatFE just hardcodes in reasonable default. The response body is limited to 8MB -- the largest hellthread I could find plus 2MB. Eight seconds was set because funny number but also it was a little above the typical loading times for my Bloat instance. 8bloat has a more interesting patch with knobs for adjusting these, but has the same defaults.
8MB is large, but it's intended to be /a/ limit. Divide the amount of megabytes you're willing to use by eight and that's roughly how many people can be serviced at once (maybe remove 10% to be safe,) which is something you can adjust and configure in your reverse proxy.
the disclosure timeline
The disclosure timeline was a point of controversy. I wanted to go over why I took the unusual route I did, which was done because of the unusual circumstances of the issue.
Bloat is not a complex client, two to three thousand lines of Go. This means the time to discover issues is much shorter than other projects. As such, time and information are things we can't afford to give to attackers. If you have a 100,000 line-long chat server, and a denial of service is /somewhere/ then you can probably justify disclosing that information. But in our case disclosing the nature of the issue narrows it down to a dangerous degree. The issue is also very trivial, the knowledge ceiling to find this issue is low.
There is also a lot of people looking for issues in software to mess with instances. Pleroma not too long ago had a zero-day, and that increased the pressure to get people patched as soon as possible and was factored in.
It was clear to me that we did need to warn admins, but it was a bad idea to disclose the nature of the issue. So I decided that warning people about the severity of the issue would be the best path forward. Because admins shutting off their Bloat instances for, say, a week was unrealistic without a good reason, I made the timeframe much shorter. The projects aren't very big, and reaching out to all the admins in a short timeframe was feasible. Also, this isn't a core service. For most people this would just mean using PleromaFE for a couple of days, and those couple of days of not using a client was worth the tradeoff of people losing data or killing important things at the hands of script kiddies.
Originally, I was going to reach out to trusted and affected fork owners to explain the issue and share a patch twenty-four hours before the public release. I wanted to make sure everyone was coordinated and ready, but wanted to account for the fact that a leak may happen. This was to give a little buffer on the off-chance the issue was leaked. Here is the original eMail I sent to @r about the issue on Monday, September 11th:
While doing an audit of 8bloat, I discovered an issue that extends to upstream Bloat. The HTTP client used for API requests is not configured with a timeout or response size limit. This allows an attacker with a malicious API to:
A - Load endless amounts of data into memory for some endpoints, exhausting the system memory
B - Exhaust the file descriptor limit by making many requests to 8bloat configured to use a malicious server that trickles data in
I've attached a rudimentary patch that fixes the issue. It only accepts responses from the instance that's less than ~8MB in size (which is well above even the largest of hellthreads I can find on FSE) and has a request timeout of eight seconds.
I'm reaching out partially to get this fixed in upstream, but also to work out a disclosure timeline. Here's what I have in mind:
0h - Pre-disclosure, encourage people to shut off their instances until the patch is ready
24h - Give patches to trustworthy people maintaining forks (basically just Pete)
48h - Push patches publicly, release full details and mitigation for people running older versions (this would be telling them to use single instance mode with a trusted instance)
Currently I plan on doing this disclosure timeline a week from now to give time for you to respond, but I'd rather coordinate with you to do it sooner (or later to a reasonable degree, if it means we can push the fixes at the same time to our repositories.)
-- webb
However, the eMail was forwarded to Pete and so the middle part was made irrelevant. There wasn't really anyone I directly knew I could contact as we don't collect telemetry or data.
I also want to respond to the really questionable point a lot of people make of me "fearmongering." In the post, I advise people to turn off their Bloat instances and wait for a patch. I specifically said that they were generic instructions to avoid disclosing the nature of the issue. It /was/ a severe issue, and I was giving advice based on the information I published alone. Nobody was forced to follow my advice, and admins could've waited closer to the full disclosure to do it. Further, if I did disclose the nature, I would've said the exact same thing sans the not using the client part. What happens when an admin shuts off their Bloat instance? The users can't use the client, which is exactly the same outcome. People aren't using their clients. Me communicating the severity upfront was an important part of getting people to prepare, and to catch people's attention in their feeds. What exactly did I have to achieve by making people use PleromaFE for a couple of days?
things i couldve done better
This is the part where I acknowledge some of the (self-)criticism in how I handled this, which were completely valid and I have zero disagreements about. This was originally after the part when I get angry, but I didn't want to bury this because I think it's an important thing for people to see.
I shouldn't have gotten as emotional and as cranky as I did, and I should've just stopped talking to the trolls and stuff until the patch release. Would people be misinformed? Yes. But I was basically poking a bee's nest, and the kinds of people falling for it weren't going to be convinced anyways I think.
I also fucked up in some communication. For example, in the Reddit post I advised people, basically, "There's a vulnerability in BloatFE/8bloat, shut off your instances and wait." The way this was worded confused people, one person even asking if they should shut down their Mastodon instance despite not installing Bloat. I should've used clearer terminology, and the assumption that people would understand what I meant clearly was wrong. I wrote the pre-disclosure as if everyone reading it was fully aware of the project. Thanks for the people who gave feedback on this.
I also should've been more transparent on my rationale. A lot of the rationale you read earlier had no reason to be held back. I did respond to people on Matrix and in the thread clarifying the things I felt was okay to talk about, but I should've added it to the original post. Thanks to the people who brought this up with me.
the part where i get angry
I am going to get angry. This includes swearing, and general drama stuff.
I'm gonna be leaking excerpts from @r's, and Pete's eMails. This is only to illustrate some misinformation beind about me in regards to this issue, and our communcations.
After sending that eMail, @r responded.
Thank you and sorry for not responding quick enough, I don't get many mails here, so don't check much often.
bloat intentionally doesn't use request timeouts because the upstream server might have different timeout duration. My own instance used to run on a relatively slow machine and many APIs took more than 8 seconds and even after switching to a fast machine, the search API usually takes more than 15 seconds for many keywords. Setting a timeout would make bloat completely unusable for certain features.
This is a fair point, continuing on...
The issues you mentioned are typical for a DoS attack and the workarounds usually depend on "how much of a target you are". These are legit issues, but I don't think a single value could work for everyone. For example, I think the proposed 8 second timeout with 8MB response size limit is still enough to DoS bloat by delaying reads on the browser/client side. Maybe providing a configurable timeout is the way to go. But then again, I don't think a timeout and a response size limit is enough the protect against DoS, even IP based ratelimiting wouldn't work against DDoS attacks.
Let me write my respon-
CC @p What do you think?
He CCed in Pete. That's kind of shitty. But Pete is a nice person to me at least, I can look past this. Nothing bad /should/ come from this but it would've been nice if he asked about looping Pete in.
Anyways, I write my response.
The request timeout issue is definitely not super severe because of client timeouts cancelling the request context, but in some configurations it might be problematic. For example, the HTTP server might care less about the overall request time, but actually care about the time it spends interacting with the client. You can't know every configuration that might be used.
The patch is moreso meant to fix the issue in the interim and provide a reasonable default that won't be vulnerable in most situations. Eight seconds is a very restrictive one, but it's best to err on the side of caution with a timeout like that.
And @r proceeds to say some slightly confusing things.
Limiting the response size would only make sense when you're requesting data from an unknown server, which is usually not the case with bloat. Users explicitly enter the domain name of the server before using bloat. And if some malicious user/client decides to connect to a malicious server, then even the smaller response size/timeout limit wouldn't help. I don't think having a limit actually fixes the "issue". I think the defaults used by the upstream server are mostly good enough that we don't have to do anything with the bloat.
I doubt that more than 10 people are actually using bloat as their primary client and the issue doesn't seem to be so critical either. So I don't think we need to be so formal about it and have disclosure timeline and such things.
After some back-and-forth, with Pete budding in, and some hiccups, I eventually I give them a proof-of-concept payload that I meant to attach with the original eMail. Whoops. At one point, Pete mentions feeling the timeline is reasonable.
I think I wouldn't worry about it unless there's a proof-of-concept that would work against a live instance. These problems seem like they'd be difficult to actually create if you were running the upstream server and making the requests to bloat but not running the bloat server. As far as the disclosure goes, I think the process outlined [in the original eMail] is reasonable.
After, @r realises what the issue is. He suggests releasing it the next day, and I panicked slightly and asked him to wait.
Please wait for me to do the pre-disclosure, this is an issue in 8bloat as well and I want to give my users a warning beforehand. If you're fine with me doing it now, I can put the message out as soon as I get the go-ahead from you (or on Monday.) From there, all I'd need is for you to wait 48h after I make the post to publish the patch. Could be done and over with as early as the day after tomorrow depending on when I hear back.
Sure, go ahead. I wanted to check whether the body returned by the http.Transport.RoundTrip is wrapped inside a gzip reader or if it happens after it, because the limit would depend on it. But it looks like it happens inside the Transport, so everything's good.
I think it'd still be possible to DoS bloat in a similar manner, although, not in a single request because of the size limit. So far, I assumed the server to be trusted because even on a public instance, users explicitely decide which server to connect to. So the attacks would involve both the client and the server. I want to play a bit with the size limit and delayed reads on the client side to see how easy it'd be to attack bloat in a similar way but with the limit and timeout applied.
Nevertheless, this patch does fix an easy way to explit bloat, so it's worth merging it. Will do it after your confirmation.
Great! We have a plan! The morning after, I release the pre-disclosure as outlined in the original eMail.
(IMPORTANT, PLEASE REPOST)
I discovered a high-severity vulnerability within BloatFE, which extends to 8bloat. I am going to release a patch in 48 hours from this post that fixes the issues. Additionally @r@freesoftwareextremist.com will push a fix to the upstream repository.
There is no known version that is unaffected. There is no evidence this issue has been exploited in the wild.
In the meantime, to stay safe:
Admins: Completely shut off your instances and wait for the patch to be released in the coming days. Do not run the server until this fix has been applied.
Users: Stop using the client and wait for more information in the coming days. Do not use the client until this fix has been applied.
(These are fairly generic instructions, I'm avoiding disclosing the nature of the issue at this time.)
There will be a few options once the patch is released:
If you're running Upstream Bloat, there will be a commit merged on the git repository to fix the issue. If you're running from git, you can run git pull. Similarly for 8bloat, we will push a fix you can pull. I will release this as pseudoversion v0.0.1.
If you're unable to pull down the commit, you can manually apply it using an unofficial patch that I will attach to the post. I will also attach a similar patch for 8bloat.
If you're unable to do either of the above, I will provide instructions for admins to mitigate the issue in BloatFE/8bloat.
In addition, I found a niche, low-severity issue that is unlikely to affect people and requires a very specific configuration.
Please spread the word, and let anyone who runs this client know about the issue.
Alright! People start sharing it. Some people are replying saying they're on standby for the patches. I clarify later why I was witholding information, and also go Linus Torvalds on someone.
thanks, taking bloat down for now. What sort of vulnerability is it? I will release a write-up shortly after the patch is released that goes into detail about the issue. Please wait until then, I want to make sure it isn't exploited ahead of the patch and people making themselves safe.
Even @r reposts! Nice! He replies too, and. Oh no.
I think you should specify that it does not affect the "users" directly.
Which is the exact kind of narrowing down I was trying to avoid. I reply in a DM,
Please delete this. I'm trying to intentionally muddy the details.
I'm saying what to do given the information, which is intentionally little.
I wait. He doesn't respond. I get fucking PISSED and eMail him.
Hey, I specifically said NOT to talk about the details publicly until the patches are out. DELETE THAT SHIT.
-- webb
Eventually he responds to my original reply on Pleroma, downplaying the issue.
I don't think that reveals too much. Besides, deletes don't actually work, but sure, I won't post any more details about it for now.
I respond, really fuming at this point but trying to get through on the off-chance he's just ignorant or something.
Just delete it man, it's to minimise the damage. You basically just leaked the fact it's not a user-side concern, which narrows it down by A LOT. The whole point is that (8)bloat doesn't have a super complicated codebase and you're making it even easier for an attacker to discover what it is.
Because 0.1% of instances don't respect the delete, does that justify keeping it up on the other 99.9% of servers? No! Of course not! But he doesn't respond. It gets worse though. Pete, responding to a person asking about the nature (which multiple times just in that thread I've said I wasn't disclosing at the time) leaks that it's a DoS issue involving a malicious upstream server.
It's a potential DoS if you have a malicious upstream server.
This narrows the issue down SIGNIFICANTLY. It went from a clean pre-disclosure to a ticking time bomb. This was also misinformation in two ways. First, it's not a "potential" DoS, it's guarantee that a remote instance can fill your memory. Second, it's not /just a DoS/. This is lying by omission. It doesn't explain the full scope of the issue. I replied in a DM, sounding like some cartoon mastermind who just had his plans to solve world hunger foiled by his pet dog.
I swear to God, first r now this. What part of a "disclosure timeline" can you fucking morons not understand? This was agreed upon ages ago. Go fuck yourselves. Seriously
This... was not productive. And might've instigated them to fuck shit up more, but I was fucking pissed. Pissed enough that I misinterpreted something he said, which was an L on my part. Particularly:
No need for that; worst that happens on your end is bloat doesn't work.
I didn't bother to look at the context, because the first post had me up to an eleven at that point. I didn't know what "your end" meant and thought this was referring to a server. He was replying to someone using PleromaFE again. I angrily replied saying it was misinformation in a DM.
He DMed back,
You announced the bug, it looks like it got disclosed, it looked like that's what we're doing. People were freaking out because it looked more serious than it was given the other recent problems. "DoS from malicious upstream" doesn't give any details but does explain the scope, which is something you have to do with the disclosure so people know what to do, otherwise it's just a non-specific threat.
At this point, I viewed Pete as being a malicious actor in this situation for a couple of reasons. First of all, I don't believe he doesn't know what happens when memory is exhausted. He hacks on operating systems and shit, he's not dumb, just dishonest here in my opinion. He's also justifying it after the fact, like @r did, instead of just communicating and collaborating. Saying "It looks like it got disclosed" when it's so fucking obvious it's a pre-disclosure can only be attributed to malice on my end. He literally thumbs-upped the original timeline, I said in the post itself and in multiple replies that I was waiting for the patch to be released to reveal information. There was no excuse for this he could think of, so he feigned ignorance.
I wrote a reply, addressing the thread. I decided to try and keep up the "maximum mitigations given the information" reccommendations. "More severe" could've meant a myriad of things, and I hoped to at least throw some attackers off with the ambiguity.
The super irresponsible actions of r and Pete are not in line with what we agreed to in terms of a timeline with disclosure of information. We agreed to not disclose information until 48 hours after the post, and they both have disrespected that. They did not reach out to me before revealing that information. Pete getting knowledge of the issue ahead of the disclosure timeline was also done without communication after I explicitly set the initial timeline to have him involved after. I attempted to ask r to delete their reply, but they refused and downplayed what they said.
They are risking users and making an issue not only for themselves but for 8bloat which is a hard independent fork. I take security issues like these seriously and they're being incredibly disrespectful and selfish instead of waiting less than two days to talk about it. Now I have to clean up the mess on my end and explain what happened to my users and leave them on constant edge during this period. This all stems from me doing a security audit on 8bloat and giving them the courtesy of working with me to make sure nobody was affected by the issue in upstream. Basic respect was not given throughout the entire process.
I'm currently monitoring for evidence of the issue being discovered. If you find evidence of an attacker finding out what it is, or if someone reveals more information that would enable an attacker to exploit the issue, please let me know so I can publish the patch early.
The issue is being downplayed now to a misleading/factually incorrect degree. DO NOT USE THE CLIENT.
I'm sorry to 8bloat users. I wish I could've seen this shit coming. I'm going to be more careful about who I disclose these kinds of issues to in the future and take a downstream-first approach.
Pete continued to downplay the issue, and mislead. I was in a position where I couldn't defend myself.
I would just like to remind people Pete is putting me in a position where I am unable to defend myself. I'm currently unable to dissect why he's wrong because I'm trying to not have people affected by the security issue. This is fucking evil shit. Please just wait the day and a half and shit on me then. Pete is wrong, that's all I'm allowed to say given the disclosure timeline.
@r responds. I'm going to break down the bullshit in this, hopefully it's obvious why I didn't publicly respond.
You know, your post caused more downtime than the vulnerability could ever have. Party because of how you worded the post and not clarifying who are affected. When I did clarify a little bit, you asked me to delete the post, 3 times actually, despite me saying that deletes don't work. We didn't agree to spread misinformation and telling everyone to stop using it.
If he's saying I replied thrice, so what? He clearly didn't read all of them -- he'd know exactly the issue with what he was saying here. I explicitly said it in the original eMail to advise people to shut their stuff down. He had plenty of opportunity to discuss first before and after the release of the pre-disclosure.
I didn't like the idea of having a "disclosure timeline" either. bloat is a small project, no where close to Pleroma and even Pleroma doesn't announce a vulnerability 2 days before the fix/actual disclosure. But you kept insisting on it, so I agreed to it thinking it's not going to hurt anyone.
This was opposed to doing both nothing and dropping a patch without warning. I didn't want to do nothing, but I was willing to be flexible if reasonable. It wasn't my issue that he didn't bring it up before, or even privately during this period. The answer to this is not to just say "FUCK OUR AGREEMENT, I DON'T CARE IF YOU JUST MADE A PROMISE TO EVERYONE."
Now I have to clean up the mess on my end and explain what happened to my users If your users are only "users", then you know they're not affected and if they do run their own public bloat instance, you can just privately share the patch with them.
please let me know so I can publish the patch early
I think that'd be the best because most people who run public instances of bloat are already aware of the issue and are simply waiting for a fix.
Great! So it's a success and did exactly what I meant it to (partially.) At this point the patch was less than a day away.
Despite all, I'm still grateful for you and thank you for discovering the issue and reporting it to me.
Go fuck your passive-aggressive shit, asshole.
Now, Pete responds.
The reason for a disclosure timeline is to give people time to apply a mitigation or patch. You give the vendor a chance to patch (that is, you and r, and to a lesser extent, me) and you give people time to apply the patches or do the mitigation. The point is to give notice to people that are affected and to give them a chance to avoid being impacted. It makes no sense to try to gag the stakeholders and panic users, so I just assumed that's not what we were doing. So I see your big announcement, people are asking me whether they need to stop using bloat, I just assume that you wouldn't be panicking people for no reason and I tell them the impact, and you start yelling at me over DMs. If the plan was "Just scare people and tell them to shut it all down because a bug exists and it might be tenuously called a security bug, but don't give them anything useful" then it should be completely understandable if I misread the plan, because no one would expect that plan.
This is, like, anti-FUD. Trying to calm people down by sowing distrust about a severe issue. Remember, Pete has orbiters that will eat this shit up, this is being said in front of an audience.
There's already a patch. There's no reason to tell everyone to turn anything off, just send the patch to people that run public instances of bloat, tell them that you'll avoid discussing the bug in public for a couple of days. Unless you explain the impact and communicated the problem to people that were affected and able to do something about the problem, you've done more harm than good. No need for extra pageantry or two days' lead time because it doesn't actually help anyone.
Last I heard, you were planning to wait an additional week anyway. If it's actually serious, you don't wait to make some small tweaks to the patch to make it configurable, you send out the patch.
This is a lie. I never said this. And again, trivial issue! Releasing the patch is releasing the explanation of what's wrong. This is not obscure algorithm issue.
Theatrics don't serve any purpose but to hype a couple of very minor bugs. I don't think I'm "evil" for letting people that use the software know about the impact (because that's what anyone would do) and crying wolf about security bugs is going to get you ignored if you actually find one; I think it's more evil to try to scare people without letting them know what's so scary.
The issue is being downplayed now to a misleading/factually incorrect degree [...]
Since I've seen the issue and am right now typing this message on bloat and have not felt the need to apply any patches to bloat, I can say that I am certain that the issue is not being downplayed but rather inflated. Theatrics don't serve any purpose but to hype a couple of very minor bugs. I don't think I'm "evil" for letting people that use the software know about the impact (because that's what anyone would do) and crying wolf about security bugs is going to get you ignored if you actually find one; I think it's more evil to try to scare people without letting them know what's so scary.
I think you get the point. Just kind of forgetting things when it's inconvienient.
I didn't respond to this because if I did it would be going back and forth in circles forever and nobody would convince anyone. Later in the thread, responding to my response to someone regarding notification of affected parties, they tried to say that the consensus was that the bug wasn't a big deal (which even @r seemed to see as a big issue.)
Yeah, I got notified, r got notified, consensus seemed to be that the bug is a bug but wasn't a big deal.
If we're doing security LARP, no one expects that "responsible disclosure" processes gag the vendor or the users.
I tried to correct this in a post, this wasn't for him, it was for others who might've actually believed this.
This was not what happened. The minor issue? Yes. The major one? No. And the emails were clear on that. I pushed against treating it as trivial until we finally agreed on the timeline. This is not just Bloat, this is also 8bloat and it affects my project too. If you disagreed or wanted to change things you should've discussed it with me privately. If the plan I laid out in the OP contradicted your interpretation of what I said, you should've discussed it with me. Same with r. Whether or not you feel it's stupid I laid public expectations and not even an hour later you both contradicted it without saying shit right under a post where I'm saying we won't talk about the nature of the issue at this time. You both can make yourselves look like shit, but this makes me look like an idiot for having you both involved. 8bloat has its own needs and policies and I made that clear multiple times during communication.
Really, this was half of the reason I was upset. I have my own project with its own goals, I extended an olive branch, we agreed on a plan, and then they embarassed me by not following it with zero communication or warning. I made a promise to people, and they broke it for me. They had plenty of opportunity to talk about it, to shift gears, and push back. Was the process unusual in that I only talked about the severity? Yes. But if things had gone according to plan, this would've benefitted users.
I stopped bothering to respond to shitty people in that thread. It was unhealthy.
a thanks
Thanks to t1c for bringing me a bit of sanity in this situation.
Thanks to people who were giving constructive criticism, even if I didn't agree with it, there's things you guys taught me that I've learned from. The criticisms that I felt wasn't warranted taught me a lot about the language and how I should go about communicating things, because that's why I think people made many of those criticisms.
Thanks to the people who shared the post, and spread the word. You did good.
Thanks to you for reading this post to the end. My arachnid.town account will go back into a slumber the day after this posts goes out.